A common Python async trap: one sync function that blocked the Liveness Probe
A python async bug I hadn’t seen in a while.
The route was async, but a heavy synchronous CPU computation inside it blocked the entire event loop.
Symptoms
POST /v1/diffrequests were slow — more so because the diff detection algorithm itself was CPU-intensive than because of audio file size.- While a diff was in progress, the Kubernetes liveness probe (
/v1/health) timed out, and kubelet restarted the container.
Container trax-audio-diff-dev failed liveness probe, will be restartThe first screenshot shows exactly this. The app blocks during diff processing, the probe fails repeatedly, and kubelet kills and restarts the container.
I’ve seen something similar before on a Java server — a synchronous /search endpoint backed by OpenSearch started taking longer and longer, hogging every thread until liveness probes couldn’t get through either, and every server restarted. This time the same thing happened with Python’s event loop.
Root cause
This was the problem.
@api_router.post("/diff")
async def align_and_diff_endpoint(
file1: UploadFile = File(..., description="First audio file (WAV)"),
file2: UploadFile = File(..., description="Second audio file (WAV)"),
bpm: Optional[float] = Form(None, gt=0, le=300, description="Beats per minute (1-300, optional)"),
) -> JSONResponse:
# ...
result = align_and_diff(
str(temp_file1),
str(temp_file2),
bpm=bpm,
output_dir=str(temp_output_dir),
save_plots=save_debug_files,
save_wav_files=save_debug_files,
)Even though the endpoint is async def, calling a CPU-bound synchronous function here blocks the event loop. That means /v1/health also sits in the queue waiting.
Fix: offload heavy work to a thread pool
Used starlette.concurrency.run_in_threadpool to move the heavy computation to a separate worker thread. Here’s the full diff:
@@ -6,18 +6,18 @@
import uvicorn
from fastapi import APIRouter, FastAPI, File, Form, HTTPException, UploadFile
+from starlette.concurrency import run_in_threadpool
from audio_diff import align_and_diff
# ===========================
# App Setup
# ===========================
@@ -162,13 +162,14 @@
save_debug_files = ENABLE_DEBUG
- result = align_and_diff(
+ result = await run_in_threadpool(
+ align_and_diff,
str(temp_file1),
str(temp_file2),
- bpm=bpm,
- output_dir=str(temp_output_dir),
- save_plots=save_debug_files,
- save_wav_files=save_debug_files,
+ bpm,
+ str(temp_output_dir),
+ save_debug_files,
+ save_debug_files,
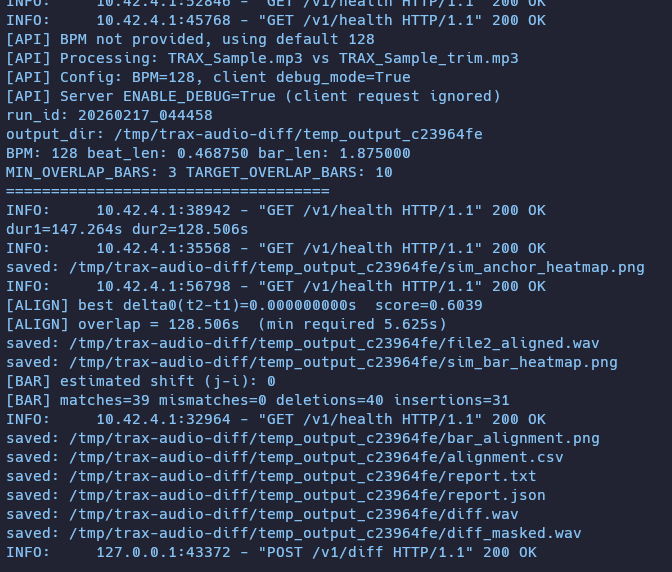
)With this one-line change, the event loop stays alive, /v1/health can be served, and the continuous pod restart issue was resolved.
After the fix, /v1/health logs appear even while diff processing is in progress — confirming that health checks now go through.
Takeaways
Slapping async on a function doesn’t make everything inside it asynchronous. CPU-bound work inside still monopolizes the event loop, and every other request stalls behind it.
This is actually a pretty common issue when working with FastAPI (or Python async in general). Run AI inference, image processing, or any heavy computation directly inside an async def route and you’ll hit the same wall. The principle is simple and the fix is just one run_in_threadpool call. Not a hard bug by any means — but after not touching Python for a while, it just came back. Had fun debugging it though.