오랜만에 만난 Python async 함정: 동기 함수 하나가 Liveness Probe를 막았다
오랜만에 보는 python async 쪽 버그라 꽤 반갑게 재밌었다.
겉보기엔 async 라우트였는데, 안쪽에서 무거운 동기 CPU 계산을 그대로 돌려버리면 이런 일이 생긴다.
증상
POST /v1/diff요청은 오디오 파일 크기보다도 diff detection 알고리즘 자체가 CPU 연산을 많이 요구하여, 처리시간이 오래 걸렸다.- 진행 중 Kubernetes liveness probe(
/v1/health)가 타임아웃되며, kubelet이 컨테이너를 재시작했다.
Container trax-audio-diff-dev failed liveness probe, will be restart첫 번째 스크린샷은 바로 이 흐름이다. diff 처리 중 앱이 블로킹되면서 probe가 반복 실패하고, 결과적으로 kubelet이 컨테이너를 종료/재기동한 로그다.
이전에 Java 서버에서도 비슷한 현상을 본 적이 있다. OpenSearch 쪽 이슈로 synchronous한 /search 엔드포인트의 처리 시간이 늘어나면서 thread를 전부 점유해버렸고, 결국 liveness probe조차 처리하지 못해 서버들이 전부 restart 된 적이 있었다. 이번에는 Python의 이벤트 루프에서 같은 현상이 재현되었다.
원인
이 부분이 문제였다.
@api_router.post("/diff")
async def align_and_diff_endpoint(
file1: UploadFile = File(..., description="First audio file (WAV)"),
file2: UploadFile = File(..., description="Second audio file (WAV)"),
bpm: Optional[float] = Form(None, gt=0, le=300, description="Beats per minute (1-300, optional)"),
) -> JSONResponse:
# ...
result = align_and_diff(
str(temp_file1),
str(temp_file2),
bpm=bpm,
output_dir=str(temp_output_dir),
save_plots=save_debug_files,
save_wav_files=save_debug_files,
)async def 엔드포인트라 해도, 여기서 CPU-bound 동기 함수가 호출되면 이벤트 루프가 블로킹된다. 그러면 /v1/health 또한 대기열에 쌓인 상태로 대기하게 된다.
수정: 무거운 작업은 스레드풀로 분리
starlette.concurrency.run_in_threadpool을 써서 무거운 연산만 별도 워커로 넘겼다. 실제 diff는 이게 전부다:
@@ -6,18 +6,18 @@
import uvicorn
from fastapi import APIRouter, FastAPI, File, Form, HTTPException, UploadFile
+from starlette.concurrency import run_in_threadpool
from audio_diff import align_and_diff
# ===========================
# App Setup
# ===========================
@@ -162,13 +162,14 @@
save_debug_files = ENABLE_DEBUG
- result = align_and_diff(
+ result = await run_in_threadpool(
+ align_and_diff,
str(temp_file1),
str(temp_file2),
- bpm=bpm,
- output_dir=str(temp_output_dir),
- save_plots=save_debug_files,
- save_wav_files=save_debug_files,
+ bpm,
+ str(temp_output_dir),
+ save_debug_files,
+ save_debug_files,
)이 한 줄 변경으로:
- 이벤트 루프가 살아있으면서,
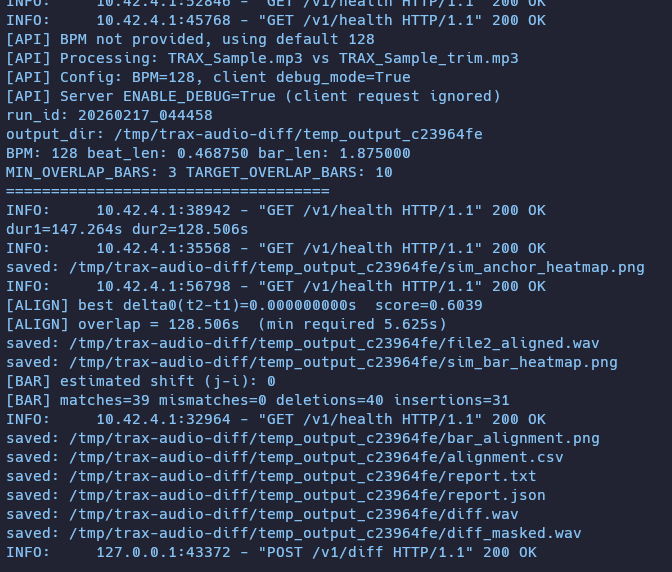
/v1/health가 처리 가능해지면서, 지속적인 Pod restart 이슈가 해결되었다.
수정 이후에는 diff 처리 중에도 /v1/health를 처리가 가능해지면서, 해당 로그가 찍히는 것을 확인할 수 있다.
정리
async만 붙인다고 해서 모든 작업이 비동기로 돌아가는 게 아니다. 그 내부의 CPU-bound 작업은 여전히 이벤트 루프를 점유하고, 그 사이 다른 요청은 전부 멈춘다.
사실 이건 FastAPI(혹은 Python async 전반)를 쓰다 보면 꽤 흔하게 마주치는 이슈다. AI inference, image processing 같은 무거운 작업을 async def 안에서 그대로 돌리면 똑같은 일이 벌어진다. 원리도 간단하고, 해법도 run_in_threadpool 한 줄이면 된다. 어려운 버그는 아니지만 — 한동안 Python을 안 쓰다가 다시 잡았더니 이렇게 찾아왔다. 덕분에 꽤 재밌게 디버깅했다.